Computer Analysis of Poetry
Author
Mark Greenberg
Title
Computer Analysis of Poetry
Description
Computer Analysis of Poetry
Category
Essays, Posts & Presentations
Keywords
URL
http://www.notebookarchive.org/2019-08-0gjicv4/
DOI
https://notebookarchive.org/2019-08-0gjicv4
Date Added
2019-08-01
Date Last Modified
2019-08-01
File Size
490.18 kilobytes
Supplements
Rights
Redistribution rights reserved

WOLFRAM SUMMER SCHOOL 2019
Computer Analysis of Poetry
Computer Analysis of Poetry
Mark Greenberg
Christoper Wolfram
Part 1: Metrical Pattern
Poets pay attention to the natural stresses in words, and sometimes they arrange words so that the stresses form patterns. Typical patterns stress every other syllable (duple meter) or every third syllable (triple meter). A convention exists to further classify poetic lines according to a unit of two or three syllables, called a foot. I choose not to follow this convention, instead looking at the line of poetry as a continuous pattern. The goal of Part 1 is to display the metrical pattern of a stanza of poetry graphically around the printed syllables.
The analyzeMeter function that does this accepts a stanza of English poetry and returns the stress pattern of the syllables. It gets the stress information from the “PhoneticForm” property in WordData and the syllabification information from the “Hyphenation” property. Sometimes words are not in WordData, or the database doesn’t have phonetic or hyphenation values for a word. In those cases we use a neural network to infer the phonetic form and/or syllabification. Also, 1-syllable words are stressed in the database, but minor words like the and and, called “stopwords” in the Wolfram Language, are usually unstressed in context. The code demotes single-syllable stopwords from stressed to undetermined. A combination of replacement rules and the SequencePredict function attempts to resolve syllables that the program has not yet determined to be stressed or unstressed.
The analyzeMeter function that does this accepts a stanza of English poetry and returns the stress pattern of the syllables. It gets the stress information from the “PhoneticForm” property in WordData and the syllabification information from the “Hyphenation” property. Sometimes words are not in WordData, or the database doesn’t have phonetic or hyphenation values for a word. In those cases we use a neural network to infer the phonetic form and/or syllabification. Also, 1-syllable words are stressed in the database, but minor words like the and and, called “stopwords” in the Wolfram Language, are usually unstressed in context. The code demotes single-syllable stopwords from stressed to undetermined. A combination of replacement rules and the SequencePredict function attempts to resolve syllables that the program has not yet determined to be stressed or unstressed.
The Phonetic/Syllabification Neural Network
This neural network takes a single word for which WordData can’t provide the phonetic and syllabic information, and returns a phonetic representation in the International Phonetic Alphabet (IPA) along with the original word divided into syllables. It is trained on WordData, which provides 27,811 words that have both phonetic and syllabic information. This set is divided into two subsets, 85% becoming the training set and 15% becoming the test set. The phonetic part of the network is a teacher forcing network, which takes three inputs during training (e.g., “formation”, “>fɔrmˈeɪʃən<”, and {“for”,”ma”,”tion”}). Each character of the English word is fed to a Long Short-Term Memory layer (LSTM). The network tries to predict the next phonetic character, the success of which is fed back to the LSTM. This pattern continues until it encounters the end-of-word character “<”. The gated recurrent layer has a second output for the syllabification of the word, which outputs a list of syllables.
This is what the training data looks like, one input and two outputs.
This is what the training data looks like, one input and two outputs.
Out[]=
Inputmilitancy,FullTargetSequence>mˈɪlətənsi<,SyllabicTarget{1,1,2,2,1,1,2,1,2} |
Inputcrowing,FullTargetSequence>krˈoʊɪŋ<,SyllabicTarget{1,1,1,2,1,1,2} |
Inputsailfish,FullTargetSequence>sˈeɪlfˌɪʃ<,SyllabicTarget{1,1,1,2,1,1,1,2} |
Inputcoo,FullTargetSequence>kˈu<,SyllabicTarget{1,1,2} |
Thanks to Timothee Verdier for extensive help with this neural network, which has an unusual architecture and had to be assembled from scratch. Here we distill from WordData all the characters in the International Phonetic Alphabet that are relevant to representing English. This becomes the list of possible characters for the phonetic feedback loop within the neural network.
In[]:=
ipaChars=Sort@DeleteDuplicates@Flatten@Characters[netInputData〚All,2〛];inputEncoder=NetEncoder[{"Characters"}];targetEncoder=NetEncoder[{"Characters",ipaChars}]
Out[]=
NetEncoder
 |
|
The net has one configuration for training, which is shown below, and a different configuration for production. In this diagram, we can see the basic structure of the network with two inputs (the training data and the “teacher” data that is fed back to be reprocessed), and two outputs (phonetic and syllabic representations). Clicking on the boxes named phoneticDecoder and sylabicDecoder will reveal the logical structure of the net’s two halves.
Out[]=
NetGraph
| uniniti aliz ed |
|
In[]:=
What the last diagram showed is then boxed and called studentNet so it can be embedded within the apparatus needed during training of the network. Notice that instead of two output ports, this “loss” version has a single output so it can keep track of the combined loss value of the syllabic and phonetic sides.
In[]:=
lossNet=NetGraph[ <| "studentNet"net ,"sylabicLoss"CrossEntropyLossLayer["Index"] ,"phoneticLoss"CrossEntropyLossLayer["Index"] ,"toPredict"SequenceRestLayer[] ,"previousAnswer"SequenceMostLayer[] ,"finalLoss"ThreadingLayer[Plus] |> , NetPort["FullTargetSequence"]"toPredict"NetPort["phoneticLoss","Target"], NetPort["FullTargetSequence"]"previousAnswer"NetPort["studentNet","Target"], NetPort["studentNet","phoneticOutput"]NetPort["phoneticLoss","Input"], NetPort["studentNet","sylabicOutput"]NetPort["sylabicLoss","Input"], NetPort["SylabicTarget"]NetPort["sylabicLoss","Target"], {"phoneticLoss","sylabicLoss"}"finalLoss"NetPort["Loss"] , "FullTargetSequence"targetEncoder]
Out[]=
NetGraph
| uniniti aliz ed |
|
The network is trained on 85% of the data collected from WordData, the remaining 15% held back for testing purposes. We halt the training after eighteen rounds because the validation loss stops improving. Continuing the training beyond that point causes overfitting, a sort of memorization of the training data rather than a holistic fitting of the features.
In[]:=
netTrainRes=NetTrain[lossNet,<|"Input"train3〚All,1〛,"FullTargetSequence"train3〚All,2〛,"SylabicTarget"train3〚All,3〛|>,All,ValidationSet<|"Input"test3〚All,1〛,"FullTargetSequence"test3〚All,2〛,"SylabicTarget"test3〚All,3〛|>,MaxTrainingRounds50]
Out[]=
NetTrain Results | ||||||||||||||||||
| ||||||||||||||||||
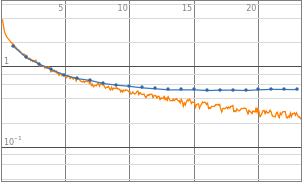
Now for the process Timothee calls surgery, cutting the part of the network that does the actual generation from the training apparatus. Note that the names of the functions mostly contain “Delete”, ”Replace”, and “Extract.”
In[]:=
trainedNet2=netTrainRes["TrainedNet"];phoTeachNet=NetDelete[trainedNet2,{"sylabicLoss","finalLoss"}];generationNet=NetDelete[trainedNet2,{"phoneticLoss","sylabicLoss","finalLoss","toPredict"}];wordEncoding=NetChain[{NetExtract[generationNet,{"studentNet",1}]},"Input"NetExtract[generationNet,"Input"]];phoneticDec=NetReplacePart[NetDelete[NetExtract[generationNet,{"studentNet","phoneticDec"}],1],"Input"NetExtract[phoTeachNet,"FullTargetSequence"]];phoneticDec=NetReplacePart[NetRename[NetAppend[NetFlatten[phoneticDec],SequenceLastLayer[]],{NetPort["Input"]NetPort["PrevPhoneticChar"]}],"Output"NetDecoder[{"Class",targetEncoder[["Encoding"]]}]];phoneticDec=NetReplacePart[NetDelete[NetExtract[generationNet,{"studentNet","phoneticDec"}],1],"Input"NetExtract[phoTeachNet,"FullTargetSequence"]];phoneticDec=NetReplacePart[NetRename[NetAppend[NetFlatten[phoneticDec],SequenceLastLayer[]],{NetPort["Input"]NetPort["PrevPhoneticChar"]}],"Output"NetDecoder[{"Class",targetEncoder[["Encoding"]]}]];phoneticDec=NetReplacePart[NetDelete[NetExtract[generationNet,{"studentNet","phoneticDec"}],1],"Input"NetExtract[phoTeachNet,"FullTargetSequence"]];phoneticDec=NetReplacePart[NetRename[NetAppend[NetFlatten[phoneticDec],SequenceLastLayer[]],{NetPort["Input"]NetPort["PrevPhoneticChar"]}],"Output"NetDecoder[{"Class",targetEncoder[["Encoding"]]}]];syllabicDec=NetExtract[generationNet,{"studentNet","sylabicDec"}];toStrChunks[x_Integer,y_]:={x,y};toStrChunks[x_List,y_]:={Last[x]+1,y};
And finally the function to call the neural network along with some sample results. Execute the code again (shift + return or shift + enter) to see a different set of words.
In[]:=
getPhonsAndSylls[word_String]:=Block[{previousAnswer=">",phonetic="",syllabic},Module[{wordenc=wordEncoding[word],stateNet},(*decodethesyllables*)syllabic=Flatten@Position[syllabicDec[wordenc],{pNonBreack_,pBreack_}/;pBreack>pNonBreack];syllabic=StringTake[word,Rest@FoldList[toStrChunks,1,syllabic]];(*decodethephonetic*)stateNet=NetStateObject[phoneticDec,<|{2,"State"}:>Last@wordenc|>];While[previousAnswer=!="<",previousAnswer=stateNet[previousAnswer];phonetic=phonetic<>previousAnswer];<|"Phonetic"StringDrop[phonetic,-1],"Syllables"syllabic|>]];testSample=RandomSample[test3,10]〚All,1〛;outputSample=Flatten[{#,Values[getPhonsAndSylls[#]]},1]&/@testSample;sampleDataset=Dataset[{<|"input"#〚1〛,"phonetic"#〚2〛,"syllabic"#〚3〛|>}&/@outputSample]
Out[]=
|
The error rate of this neural network is about 9.9% on the phonetic output and 4.1% on the syllabic. The phonetic error is somewhat high, but as this is a backup for words without the “PhoneticForm” property in WordData, the errors will impact the performance of the analysis only rarely. Improvements may be achieved by training the neural net with a larger set of data or tweaking its parameters.
Analysis of Meter
The first stanza of Edgar Allan Poe' s "The Raven" will serve as our example for analyses. This was copied from a website, www.poetryfoundation.org/poems/48860/the-raven. I changed only the appearance of new-lines from literal breaks to “\n”. Punctuation, capitalization, and quotation marks will all be processed by the analyzing code.
In[]:=
stanza="Once upon a midnight dreary, while I pondered, weak and weary,\nOver many a quaint and curious volume of forgotten lore—\nWhile I nodded, nearly napping, suddenly there came a tapping,\nAs of some one gently rapping, rapping at my chamber door.\n“’Tis some visitor,” I muttered, “tapping at my chamber door—\nOnly this and nothing more.”";
We extract the meter, phonetic representation, and syllabification for each word of the poem. The first ten are shown here. Some subtleties include identification of one-syllable stop words, which are marked as stressed in WordData but often not stressed in context, and a cross-check between the meter and syllables to make sure they agree.
Out[]=
|
We have labeled each syllable that is definitely stressed with a 1, and each that is definitely unstressed with a zero. Ambiguous syllables we have marked with .5. Stress patterns are binary, so we must resolve the .5 syllables to either 1 or 0. We use a two-tier approach for this. First we apply a series of six replacement rules because English prefers not to run three stressed or three unstressed syllables consecutively. After that, I apply the SequencePredict function to find which of the possible remaining patterns best matches known poetic forms (the duple meter and triple meter mentioned at the beginning). No ambiguous syllable stresses remain after that step.
Out[]=

The zigzag lines zig up for stressed syllables and down for unstressed. The last stressed syllable of each line is aligned because this will make the end rhyme more apparent in Part 2 of the project. The program’s analysis of this stanza matches exactly traditional scansion except for one mistake in syllabification, which it marks with the number 11, and the word “a” in the second line which should be unstressed. Poe is using a duple meter pattern, which alternates stressed and unstressed syllables. The graphic shows clearly that the overall framework alternates stressed-unstressed-stressed.... Where there are deviations from this pattern, the poet deliberately added an extra syllable or introduced an unexpected stress. I suggest that this graphic makes more metrical information readily available than the traditional method of marking feet above a line of text.
Part 2: Rhyme
Poems often rhyme. A naive explanation of rhyme says that one word rhymes with another if the ending sounds are the same, particularly the last vowel sounds and beyond. Rhyme in context is more complicated than that, and the concept of rhyme can be extended to a larger class of what we might call sound echoes. Inside a poem, we really are not rhyming one word with another. Instead, we rhyme one part of the stress pattern with another. It is always the same part of the pattern, a stressed syllable followed by zero to two unstressed syllables. With this definition, we can understand rhymes like “...pick it...” with “thicket” and “Lenore” with “nevermore”. The term rhyme can include a larger family of sound features in a poem. Here, we will consider traditional rhyme (end rhyme), alliteration (front rhyme), assonance (vowel rhyme), and consonance (consonant rhyme). Poets are certainly aware of these echoic features, often plying them for effect. With the help of the Wolfram Language, we will attempt to represent these rhymes in an informative way.
The neural network in Part 1 gives the phonetic representation of the entire word and the word separated into syllables. To map the sound features of the poem, we need also the phonetic representation of each syllable. Several solutions to this problem are possible. We could modify the neural network to give a third output of phonetic syllables. We could use each word’s phonetic representation and split it into the right number of syllables. This would maintain the proper phoneme sounds, but it would often divide the consonants differently than the plain English syllables. A better solution is to get a phonetic representation of the individual syllables we have already. This solution is not perfect, but it does give divisions that are consistent with the scheme we are using.
We create an indexed list of all the phonetic syllables and then use the Subsets function to get a list of all 3655 possible pairs.
The neural network in Part 1 gives the phonetic representation of the entire word and the word separated into syllables. To map the sound features of the poem, we need also the phonetic representation of each syllable. Several solutions to this problem are possible. We could modify the neural network to give a third output of phonetic syllables. We could use each word’s phonetic representation and split it into the right number of syllables. This would maintain the proper phoneme sounds, but it would often divide the consonants differently than the plain English syllables. A better solution is to get a phonetic representation of the individual syllables we have already. This solution is not perfect, but it does give divisions that are consistent with the scheme we are using.
We create an indexed list of all the phonetic syllables and then use the Subsets function to get a list of all 3655 possible pairs.
In[]:=
syllab2=Flatten[#]&/@Reverse[syllab];phonSylls=Flatten[MapIndexed[{StringDelete[WordData[#1,"PhoneticForm"]/._MissinggetPhonsAndSylls[#1]["Phonetic"],"ˈ"|"ˌ"],#2}&,syllab2,{2}],1];allPairs=Subsets[phonSylls,{2}];{Short[phonSylls],Short[allPairs]}//Column
Out[]=
nɛ,{1,1},{ʌp,{1,2}},{ɒn,{1,3}},{ə,{1,4}},mɪd,{1,5},76,ðɪs,{6,3},{ænd,{6,4}},{nɒθ,{6,5}},ɪŋ,{6,6},{mɔr,{6,7}} |
nɛ,{1,1},{ʌp,{1,2}},nɛ,{1,1},{ɒn,{1,3}},3651,{{nɒθ,{6,5}},{mɔr,{6,7}}},ɪŋ,{6,6},{mɔr,{6,7}} |
We can find the various kinds of echoes. For now we will not consider the stress values of the syllables. There are 185 alliterative pairs, but only 19 close enough to be heard as echoic features of the poem.
Out[]=
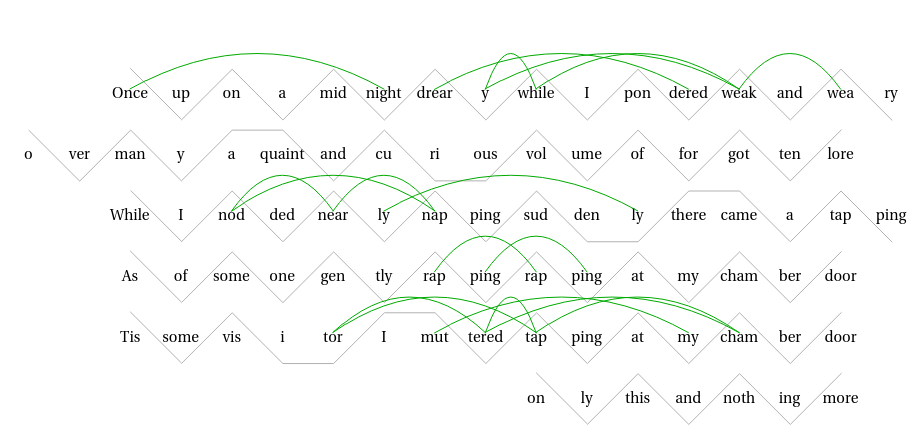
Some alliterations ring louder than others, and we can analyze that too. If the alliteration is between two stressed syllables, then we hear the echo clearly. If not, then the echo is faint. This could be represented by line thickness or transparency.
For consonance, which is the repetition of consonant sounds anywhere in two syllables, we change the code slightly.
Out[]=

And again for assonance, the echo of vowel sounds, the code is slightly different.
Out[]=

The echoes of traditional end rhyme, what we commonly think of as rhyme, are more difficult to map because they can span multiple lines, they involve groups of syllables, and they are restricted to certain parts of the metrical pattern. This takes some prep work. We will gather a list of rhyme candidates and then test them for identical phonetic endings.
Out[]=

One might object that rapping doesn’t rhyme with rapping. It does echo, so I included such repetitions. Eliminating them is as simple as adjusting the matching criterion in the line that begins endRhymes = .
Conclusion
With a computer we can inspect more than just a poem’s meter and rhyme. The placement of natural stops and the poet’s tendency to twist expected syntax also await computational analysis, but those are paths to be explore another time.
It is easy to get drawn into thinking that poems are these beautiful flowers of emotional expression and miss the craft that molds them from natural language. If we had a way to see some of that craft, to extract and visualize the interplay between sculptor and verbal clay, perhaps that would lead to a better understanding... and maybe even a deeper appreciation. Isn’t a flower that much more wonderful if you recognize the Fibonacci sequence swirling around its center?
It is easy to get drawn into thinking that poems are these beautiful flowers of emotional expression and miss the craft that molds them from natural language. If we had a way to see some of that craft, to extract and visualize the interplay between sculptor and verbal clay, perhaps that would lead to a better understanding... and maybe even a deeper appreciation. Isn’t a flower that much more wonderful if you recognize the Fibonacci sequence swirling around its center?
Cite this as: Mark Greenberg, "Computer Analysis of Poetry" from the Notebook Archive (2019), https://notebookarchive.org/2019-08-0gjicv4
Download
