Simplified Machine-Learning Workflow #7
Author
Anton Antonov
Title
Simplified Machine-Learning Workflow #7
Description
Semantic Analysis (Part 2)
Category
Educational Materials
Keywords
URL
http://www.notebookarchive.org/2020-09-55srdob/
DOI
https://notebookarchive.org/2020-09-55srdob
Date Added
2020-09-11
Date Last Modified
2020-09-11
File Size
2.92 megabytes
Supplements
Rights
Redistribution rights reserved

Here is the of this notebook.
recordedvideo
Latent Semantic Analysis (Part 2)
Latent Semantic Analysis (Part 2)
A Wolfram livecoding session
Anton Antonov
December 2019
December 2019
Session overview
Session overview
1
.Motivational example -- full blown LSA workflow.
2
.Fundamentals, text transformation (the hard way):
2
.1
.bag of words model,
2
.2
.stop words,
2
.3
.stemming.
3
.Data
Data
Out[]=
|
Dimensionality reduction functions at WFR
Dimensionality reduction functions at WFR
Full LSA workflow (over Raku documentation)
Full LSA workflow (over Raku documentation)
Raku?
Raku?
Formerly known as “Perl 6”.
In[]:=
WebImage["https://www.raku.org"]
Out[]=

Where from?
Where from?
In[]:=
WebImage["https://github.com/Raku/doc"]
Out[]=
Natural language commands
Natural language commands
In[]:=
lsaNCRakuDoc=ToLSAMonWLCommand["create with aDocuments;make the document term matrix;show data summary;apply the LSI functions IDF, TermFrequency, Cosine;extract 36 topics using the method NNMF and 12 max steps;show the topics table with 9 table columns;show thesaurus table of regex, array, chars, role, grammar;"];
Explanations the hard way
Explanations the hard way
In[]:=
Topics extraction
Topics extraction
In[]:=
movieReviews=ExampleData[{"MachineLearning","MovieReview"},"Data"];Dimensions[movieReviews]
Out[]=
{10662}
In[]:=
movieReviews〚All,2〛="tag:"<>#&/@movieReviews〚All,2〛;
In[]:=
aMovieReviews=AssociationThread[Range[Length[movieReviews]]Map[StringRiffle[List@@#," "]&,movieReviews]];RandomSample[aMovieReviews,2]
Out[]=
5468if you value your time and money , find an escape clause and avoid seeing this trite , predictable rehash . tag:negative,5384imagine the cleanflicks version of 'love story , ' with ali macgraw's profanities replaced by romance-novel platitudes . tag:negative
In[]:=
aMovieReviews=Select[aMovieReviews,StringQ[#]&&StringLength[#]>10&];RandomSample[aMovieReviews,2]
Out[]=
1135beautifully observed , miraculously unsentimental comedy-drama . tag:positive,1692flawed , but worth seeing for ambrose's performance . tag:positive
In[]:=
aMovieReviews2=DeleteStopwords[Select[StringSplit[#],StringLength[#]>0&]]&/@aMovieReviews;
In[]:=
aMovieReviews2〚1;;12〛
Out[]=
1{rock,destined,21st,century's,new,",conan,",going,make,splash,greater,arnold,schwarzenegger,,,jean-claud,van,damme,steven,segal,.,tag:positive},2{gorgeously,elaborate,continuation,",lord,rings,",trilogy,huge,column,words,adequately,describe,co-writer/director,peter,jackson's,expanded,vision,j,.,r,.,r,.,tolkien's,middle-earth,.,tag:positive},3{effective,too-tepid,biopic,tag:positive},4{sometimes,like,movies,fun,,,wasabi,good,place,start,.,tag:positive},5{emerges,rare,,,issue,movie,honest,keenly,observed,feel,like,.,tag:positive},6{film,provides,great,insight,neurotic,mindset,comics,--,reached,absolute,top,game,.,tag:positive},7{offers,rare,combination,entertainment,education,.,tag:positive},8{picture,literally,showed,road,hell,paved,good,intentions,.,tag:positive},9{steers,turns,snappy,screenplay,curls,edges,;,clever,want,hate,.,somehow,pulls,.,tag:positive},10{care,cat,offers,refreshingly,different,slice,asian,cinema,.,tag:positive},11{film,worth,seeing,,,talking,singing,heads,.,tag:positive},12{really,surprises,wisegirls,low-key,quality,genuine,tenderness,.,tag:positive}
In[]:=
lsLongForm=Join@@MapThread[Thread[{##}]&,Transpose[List@@@Normal[aMovieReviews2]]];
In[]:=
Dataset[RandomSample[lsLongForm,40]]
Out[]=
| |||||||||||||||||||||||||||||||||||||||||||
In[]:=
aStemRules=Dispatch[Thread[Rule[#,WordData[#,"PorterStem"]&/@#]]&@Union[lsLongForm〚All,2〛]];lsLongForm〚All,2〛=lsLongForm〚All,2〛/.aStemRules;
In[]:=
aTallies=Association[Rule@@@Tally[lsLongForm〚All,2〛]];aTallies=Select[aTallies,#>20&];Length[aTallies]
Out[]=
981
In[]:=
TakeLargest[aTallies,12]
Out[]=
.14010,,10037,tag:neg5331,tag:posit5331,film1659,movi1476,like805,"655,--630,make611,stori519,time463
In[]:=
lsLongForm=Select[lsLongForm,KeyExistsQ[aTallies,#〚2〛]&&StringLength[#〚2〛]>2&];
In[]:=
ctObj=ResourceFunction["CrossTabulate"][lsLongForm,"Sparse"True];
In[]:=
ResourceFunction["CrossTabulate"][RandomSample[lsLongForm,12]]
Out[]=
|
In[]:=
CTMatrixPlot[x_Association/;KeyExistsQ[x,"SparseMatrix"],opts___]:=MatrixPlot[x["SparseMatrix"],Append[{opts},FrameLabel{{Keys[x][[2]],None},{Keys[x][[3]],None}}]];CTMatrixPlot[ctObj]
Out[]=

In[]:=
matCT=N[ctObj["SparseMatrix"]];
In[]:=
ResourceFunction["ParetoPrinciplePlot"][Total[matCT,{1}]]
Out[]=

In[]:=
matCT=matCT.SparseArrayDiagonalMatrixLogDimensions[matCT]1Total[matCT,{1}];
In[]:=
matCT=matCT/Sqrt[Total[matCT*matCT,{2}]];
In[]:=
SeedRandom[8966]matCT2=matCT〚RandomSample[Range[Dimensions[matCT]〚1〛],4000],All〛
Out[]=
SparseArray
 |
|
In[]:=
SeedRandom[23];AbsoluteTiming{W,H}=
[matCT2,24,MaxSteps12,"Normalization"Right];
ResourceFunction[ |
Out[]=
{14.5987,Null}
In[]:=
Dimensions[W]
Out[]=
{4000,24}
In[]:=
Dimensions[H]
Out[]=
{24,946}
matCT2≈W.H
In[]:=
Multicolumn[Table[Column[{Style[ind,Blue,Bold],ColumnForm[Keys[TakeLargest[AssociationThread[ctObj["ColumnNames"]->Normal[H〚ind,All〛]],10]]]}],{ind,Dimensions[H]〚1〛}],8,DividersAll]
Out[]=
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
Statistical thesaurus
Statistical thesaurus
In[]:=
SeedRandom[898];rinds=Flatten[Position[ctObj["ColumnNames"],#]&/@Map[WordData[#,"PorterStem"]&,{"tag:positive","tag:negative","book","amusing","actor","plot","culture","comedy","director","thoughtful","epic","film","bad","good"}]];rinds=Sort@Join[rinds,RandomSample[Range[Dimensions[H]〚2〛],16-Length[rinds]]];Multicolumn[Table[Column[{Style[ctObj["ColumnNames"]〚ind〛,Blue,Bold],ColumnForm[ctObj["ColumnNames"]〚Flatten@Nearest[Normal[Transpose[H]]"Index",H〚All,ind〛,12]〛]}],{ind,rinds}],8,DividersAll]
Out[]=
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
The easy way
The easy way
In[]:=
SeedRandom[23];lsaMovieReviews=LSAMonUnit[RandomSample[aMovieReviews,4000]]⟹LSAMonMakeDocumentTermMatrix[{},Automatic]⟹LSAMonEchoDocumentTermMatrixStatistics⟹LSAMonApplyTermWeightFunctions["IDF","TermFrequency","Cosine"]⟹LSAMonExtractTopics["NumberOfTopics"24,"MinNumberOfDocumentsPerTerm"20,Method"NNMF",MaxSteps20]⟹LSAMonEchoTopicsTable["NumberOfTableColumns"8];
»
Context value "documentTermMatrix":
Dimensions: | Density: | |||||||||||||||||
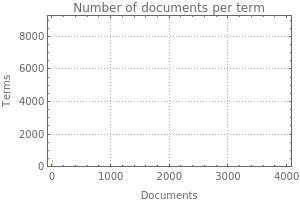 |  |
| ||||||||||||||||
»
topics table:
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
In[]:=
lsaMovieReviews⟹LSAMonEchoStatisticalThesaurus["Words"{"film","movie","director","bad","good"}];
»
statistical thesaurus:
term | statistical thesaurus entries |
bad | {bad,idea,negative,certainly,acting,sort,cinema,good,entertainment,dialogue,actors,direction} |
director | {director,girl,say,tale,world,art,times,visual,john,bit,narrative,self} |
film | {film,good,way,look,thing,positive,sweet,surprisingly,comedy,smart,documentary,original} |
good | {good,way,short,ending,director,young,predictable,simply,rare,cast,ultimately,thing} |
movie | {movie,negative,performances,little,make,kind,going,slow,want,great,pretty,better} |
Eat your own dog food
Eat your own dog food
Q & A with study group at Stony Brook University, New York
Q & A with study group at Stony Brook University, New York
In[]:=
WebImage["https://github.com/antononcube/MathematicaForPrediction/blob/master/Data/Big-Data-in-Healthcare/HHA-551-Questions-for-Anton.txt"]
Out[]=

In[]:=
WebImage["https://healthtechnology.stonybrookmedicine.edu/programs/ahi/course-schedule"]
Out[]=

Calculations
Calculations
In[]:=
lsQuestions=Import["https://raw.githubusercontent.com/antononcube/MathematicaForPrediction/master/Data/Big-Data-in-Healthcare/HHA-551-Questions-for-Anton.txt"];lsQuestions=StringSplit[lsQuestions,"\n"];Length[lsQuestions]
Out[]=
99
In[]:=
RandomSample[lsQuestions,5]
Out[]=
{ Q3: What is the very first step you take when cleaning an enormous data set., 4. What kind of impact do you see AI having on the role of a data scientist in the next few years?, 2. All the data management tools are prone to manipulation by certain individuals to achieve an end. How well can the tools be designed to minimize such manipulation?, 2. How do visualizations on R Studio compare to Tableau?, 2. You mentioned you had a background working with recommendation engines such as the one on Netflix before working in healthcare, Has this helped you in the healthcare side of your career? Have you used or created anything similar to a recommendation engine in healthcare?}
In[]:=
lsaBigDataQuestions=LSAMonUnit[lsQuestions]⟹LSAMonMakeDocumentTermMatrix[{},Automatic]⟹LSAMonApplyTermWeightFunctions["IDF","TermFrequency","Cosine"]⟹LSAMonExtractTopics["NumberOfTopics"8,"MinNumberOfDocumentsPerTerm"2,Method"NNMF",MaxSteps20]⟹LSAMonEchoTopicsTable["NumberOfTableColumns"8]⟹LSAMonFindMostImportantDocuments[12]⟹LSAMonEchoFunctionValue[GridTableForm[#,TableHeadings{"Score","Index","ID","Document"}]&];
»
topics table:
|
|
|
|
|
|
|
|
»
# | Score | Index | ID | Document |
1 | 1. | 38 | id.038 | 10. When you were developing digital media recommendation algorithms, what feedback did you get? Did it help meaningfully improve the code? Did you find having more information about an individual improved retention rates of recommendations? |
2 | 0.156755 | 35 | id.035 | 7. How much emphasis do you place on coding techniques like scripting, especially to help process huge amounts of data within a reasonable time frame? Are there other techniques you use to help expedite data processing? |
3 | 0.0507546 | 42 | id.042 | 3. What skills does an individual require in order to be a success at data analytics? |
4 | 0.0506242 | 48 | id.048 | 2. You mentioned you had a background working with recommendation engines such as the one on Netflix before working in healthcare, Has this helped you in the healthcare side of your career? Have you used or created anything similar to a recommendation engine in healthcare? |
5 | 0.0506242 | 55 | id.055 | 2. You mentioned you had a background working with recommendation engines such as the one on Netflix before working in healthcare, Has this helped you in the healthcare side of your career? Have you used or created anything similar to a recommendation engine in healthcare? |
6 | 0.0457088 | 37 | id.037 | 9. Do you think upcoming data analysts and scientists should be more well-rounded in their education? If so, do you think this can help address some of the shortcomings experienced by current AI implementations? |
7 | 0.0146716 | 31 | id.031 | 3. In the hiring process, most organizations look out for experienced people or at least someone from a healthcare background. How can a fresh graduate with no healthcare background or sufficient experience tap into the informatics field? |
8 | 0.00854905 | 56 | id.056 | 3. In one of our other classes we are learning about the ETL process and OMOP standards, when you’ve cleaned data in the past have you used the ETL process? If so, How was it done through R? |
9 | 0.00854905 | 49 | id.049 | 3. In one of our other classes we are learning about the ETL process and OMOP standards, when you’ve cleaned data in the past have you used the ETL process? If so, How was it done through R? |
10 | 0.00776817 | 69 | id.069 | 2. What would a day in the life of an R Studio –using analyst look like? |
11 | 0.00772403 | 34 | id.034 | 6. Are there any up-and-coming programming languages we should be aware of, especially with regards to Big Data? |
12 | 0.00657614 | 2 | id.002 | 2. Is there anything besides R that you suggest students take time to learn individually? |
Visualization with a bipartite graph
Visualization with a bipartite graph
In[]:=
gr=lsaBigDataQuestions⟹LSAMonSetValue[None]⟹LSAMonNormalizeMatrixProduct[NormalizedLeft]⟹LSAMonMakeGraph["Type""Bipartite","Thresholds"{0.2,1}]⟹LSAMonTakeValue;
The red nodes are the questions, the blue nodes are the words.
In[]:=
HighlightGraph[Graph[gr,VertexLabels"Name",EdgeStyle{Gray,Opacity[0.4]}],Flatten[StringCases[VertexList[gr],"id."~~__]],ImageSize1000]
Out[]=

Cite this as: Anton Antonov, "Simplified Machine-Learning Workflow #7" from the Notebook Archive (2020), https://notebookarchive.org/2020-09-55srdob
Download
